![[PyTorch] 파이토치로 딥러닝 - MLP Network으로 FashionMNIST Dataset Classification 해보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FXOYJ8%2FbtrgArh5ZMb%2FRvNAu08SDKqLF9c6KYfoUk%2Fimg.png)
예전에 VS Code로 Anaconda / JupyterNotebook 연동하기,
새로 만든 Kernel에 PyTorch 깔아서 VS Code 상에서
돌려보기까지 해보고 글을 작성했었다.
그 후로 짬 날 때마다 PyTorch 예제 code를
이것저것 건드려보고 line-by-line로 공부했고,
글으로 정리해보려 한다.
단, 딥러닝의 아주 기본적인 개념들은
다른 블로거나 유튜버 분들이
잘 다뤄주신 자료가 많으므로 생략하겠다.
0. 관련 글 리스트
1. 전체 코드 및 Network Overview
일단 전체 코드부터 표시하자면 이렇다.
알짜배기 코드들은 PyTorch Tutorial 웹페이지에서
보고 그대로 따라한 수준이고,
결과로 print 되면서 나오는 부분만 (Accuracy/Loss)
조금 수정해서 좀 더 보기 편하게 만들어놨다.
빠른 시작(Quickstart) — PyTorch Tutorials 1.9.0+cu102 documentation
Note Click here to download the full example code 파이토치(PyTorch) 기본 익히기 || 빠른 시작 || 텐서(Tensor) || Dataset과 Dataloader || 변형(Transform) || 신경망 모델 구성하기 || Autograd || 최적화(Optimization) || 모델 저
tutorials.pytorch.kr
<<코드가 보이지 않는다면 오른쪽 아래의 달모양 버튼으로
테마를 다크모드에서 화이트모드로 바꿔주세요>>
############################################################
# Import the Libraries
############################################################
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('CUDA:', torch.cuda.is_available(), ' Use << {} >>'.format(device.upper()))
print('PyTorch Version:', torch.__version__)
############################################################
# Get the Dataset
############################################################
# Download Dataset
train_data = datasets.FashionMNIST(
root='data', train=True, download=True, transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root='data', train=False, download=True, transform=ToTensor()
)
# Build DataLoader
batch_size = 64
trainloader = DataLoader(
train_data, batch_size=batch_size
)
testloader = DataLoader(
test_data, batch_size=batch_size
)
# Check the Shape of Dataset
for X, y in testloader:
print('Shape of X [N, C, H, W]:\n', X.shape)
print('Shape of y:\n', y.shape, '\n', y.dtype)
break # Run For Loop Once
# Plot the Test Data from Dataset
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
fig = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(train_data), size=(1,)).item()
img, label = train_data[sample_idx]
fig.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
############################################################
# Build the Classifier, Train, and Test Function
############################################################
# Build NN
class Net(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
Net_Out = self.layer(x)
return Net_Out
# Build Train Function
def train(dataloader, model, loss_fn, optimizer):
pbar = tqdm(dataloader, desc=f'Training')
for batch, (X, y) in enumerate(pbar):
# X, y = X.to(device), y.to(device)
# Feedforward
pred = model(X)
# Calc. Loss
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Build Test Function
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
loss, correct = 0,0
with torch.no_grad():
for X, y in dataloader:
# X, y = X.to(device), y.to(device)
pred = model(X)
loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
loss /= num_batches
correct /= size
print(f'Test Accuracy: {(100*correct):>0.1f}% Loss: {loss:>8f} \n')
return 100*correct, loss
############################################################
# Run the Training and Evaluation
############################################################
# Generate the Model
model = Net().to(device)
# Set the Training Parameters
lr = 1e-3
loss_fn = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=lr)
# Plot
fig = plt.figure(figsize=(20,5))
line1, line2 = plt.plot([],[],[],[])
plt.clf()
# Train the Network
epochs = 100
for t in range(epochs):
print(f'----- Epoch {t+1} -----')
train(trainloader, model, loss_fn, optimizer)
accuracy, loss = test(testloader, model, loss_fn)
# Add Accuracy & Loss to the Lines
line1.set_xdata(np.append(line1.get_xdata(), t+1))
line1.set_ydata(np.append(line1.get_ydata(), loss))
line2.set_ydata(np.append(line2.get_ydata(), accuracy))
fig.add_subplot(1,2,1)
plt.plot(line1.get_xdata(), line1.get_ydata(), color='red')
plt.plot(line1.get_xdata(), line1.get_ydata(), 'o', color='red')
plt.xlabel('Epoch', fontsize=12); plt.ylabel('Loss', fontsize=12)
fig.add_subplot(1,2,2)
plt.plot(line1.get_xdata(), line2.get_ydata(), color='blue')
plt.plot(line1.get_xdata(), line2.get_ydata(), 'o', color='blue')
plt.xlabel('Epoch', fontsize=12); plt.ylabel('Accuracy', fontsize=12)
plt.tight_layout()
plt.autoscale()
plt.show()
위 코드를 통해 돌리게 될 network는
아래 그림과 같이 생겼다.

2. Library Import 하기
############################################################
# Import the Libraries
############################################################
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('CUDA:', torch.cuda.is_available(), ' Use << {} >>'.format(device.upper()))
print('PyTorch Version:', torch.__version__)
Neural Network의 Training 및 Evaluation을 할 때
Accuracy/Loss의 그래프를 좀 그려보려고
NumPy와 MatPlotLib을 불러왔다.
그리고 tqdm을 불러왔는데,
PyTorch Tutorial을 보면 결과 print가
좀 지저분하게 되는 느낌이라 나는 이게 싫어서
progress를 percent bar로 나타내고 싶었다.
tqdm을 사용하려면 terminal에 아래 code를 입력해
library를 설치해줘야 한다.
pip install tqdm
그리고, Neural Network를 다루기 위해
필요한 library인
Torch 및 관련 method들을 불러왔다.
3. Dataset 가져오기
############################################################
# Get the Dataset
############################################################
# Download Dataset
train_data = datasets.FashionMNIST(
root='data', train=True, download=True, transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root='data', train=False, download=True, transform=ToTensor()
)
# Build DataLoader
batch_size = 64
trainloader = DataLoader(
train_data, batch_size=batch_size
)
testloader = DataLoader(
test_data, batch_size=batch_size
)
# Check the Shape of Dataset
for X, y in testloader:
print('Shape of X [N, C, H, W]:\n', X.shape)
print('Shape of y:\n', y.shape, '\n', y.dtype)
break # Run For Loop Once
# Plot the Test Data from Dataset
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
fig = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(train_data), size=(1,)).item()
img, label = train_data[sample_idx]
fig.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
딥러닝에서 사용되는 가장 기본적인 dataset은 MNIST이다.
MNIST는 0, 1, 2, 3, .. 9 까지의
흑백 손글씨 image를 모아놓은 dataset인데,
PyTorch Tutorial 에서는 FashionMNIST 라고 해서
마찬가지로 흑백의 옷/신발 등과 같은 사물들의
image를 모아놓은 dataset을 사용하여 PyTorch 사용법을 소개한다.
library를 import하는 과정에서
torchvision의 dataset을 가져왔으므로,
dataset.FashionMNIST라고만 call을 해줘도
download가 가능해진다.
8번~11번 line을 보면 argument로
root, train, download, transform이 있는 것을 볼 수 있다.
root는 다른 이름으로 저장을 할 건데 어디로 받을건지에 해당한다.
현재 폴더에 data라는 이름의 폴더를 만든 뒤
여기에 dataset을 내려받게 된다.
train은 True로 두면 Training Set이고 되고 False로 두면 Test Set이 된다.
각각 train_data / test_data 로 variable 설정을 하였다.
transform은 다운받은 data의 format을
PyTorch에서 사용하는 tensor로 바꿔준다는 의미이다.
NumPy에서는 ndarray를 쓰고
PyTorch에서는 tensor를 쓴다.
그냥 인터넷에 굴러다니는 JPG image 같은거 맘대로 갖다놓는다고
PyTorch가 알아서 다 처리해 주길 기대할 수는 없으니까.
이걸 위해 library import쪽에서 torchvision.transforms.ToTensor
를 가져온 것이다.
그 다음으로 나오는 건 DataLoader이다.
이걸 보고 처음에 든 생각은,
Dataset을 Download 해서 가져왔으면 가져온거지 또 뭘 load 한다는거야?
였다. 이 짓을 하는 이유는, training code 짜는 것을
좀 더 편하게 만들어주기 위함이다.
먼저, Mini Batch를 뽑아서 training에 쓴다는 개념을 이해해야 한다.
지금 여기서 다루는 dataset은 FashionMNIST로,
dataset 크기가 별로 크지도 않고 큰 문제가 되지 않을 수 있지만,
ImageNet과 같이 엄청나게 큰 dataset을 train 한다고 생각한다면
모든 data를 한 번에 다 load 해와서
loss를 계산하고 gradient를 계산하는 등의
training 과정을 거치는 것은 시간 효율이 매우 좋지 않다.
(수천만원짜리 GPU 서버로 training code를 돌리더라도
ImageNet 같은 건 주 단위로 시간이 걸린다)
따라서, 전체 data를 작은 batch 단위로 쪼갠 뒤 training을 하고,
progress를 봐 가면서 이게 잘 되는지 안 되는지
중간에 자주 확인하는 것이 훨씬 효율적이다.
(아래 Stanford의 Andrew Ng 교수님의 강의를 참고.)
(Mini-Batch를 통한 training에는 사실 Batch Normalization 이란
technique이 큰 의미를 가지긴 한데, 이 얘기는 나중에 ..)
그리고, DataLoader는 dataset 내 data를
iterable하게 만들어준다는 것에 큰 의미가 있다.
이게 무슨 말인지는 training 쪽 code를 보면 알 수 있는데,
batch_size만 정해주면 DataLoader를 enumerate하여
for loop으로 돌아가도록 배치해놓기만 해도
지가 알아서 batch_size만큼 쏙쏙 뽑아내서
training을 dataset의 끝까지 진행한다.
이게 겁나게 편한 부분인데,
예를 들어 dataset의 length가 10이고 batch_size가 3이라면
마지막 남은 1에 대한 code를 어떻게 짤지 고민할 필요도 없이
알아서 3, 3, 3, 1의 순서로 batch를 뽑아
training loop이 자연스럽게 돌아가도록 만들어준다.
DataLoader의 첫번째 argument는 dataset이다.
즉, code를 dataset=train_data 및 dataset=test_data로 바꿔도 된다.
DataLoader의 다른 argument로는
shuffle=True 등과 같은 option도 있는데,
여기선 일단 기본적으로만 했다.
DataLoader의 data를 좀 뽑아내 print를 하는 code를 돌려보면,
FashionMNIST의 image에 대한 정보를 알 수 있다.
for X, y in test_dataloader:
print('Shape of X [N, C, H, W]:\n', X.shape)
print('Shape of y:\n', y.shape, '\n', y.dtype)
break # Run For Loop only Once
위 code를 돌리면 아래와 같이 나온다.
Shape of X [N, C, H, W]:
torch.Size([64, 1, 28, 28])
Shape of y:
torch.Size([64])
torch.int64
여기서 X는 image data가 batch_size만큼 묶여 있는 형태이다.
나는 batch_size를 64로 두었으므로 N이 64가 나왔다.
C는 channel인데, RGB image면 3이지만 흑백 image므로 1이 나온다.
H, W는 height/width이다. 28 x 28 pixel의 image를 뜻한다.
y는 image data의 label이다.
이게 T-Shirt인지, Dress인지, Bag인지 여부를
0~9에 해당하는 숫자에 대응시켜놓은 것.
batch_size가 64이므로, 64개씩 뭉텅이로 image를 뽑아놓은 상태이며
64개 image에 대한 단일 label이 있어야 하므로 y의 size는 64이다.
그리고 label들은 0~9의 숫자로 할당되어 있으므로 datatype은 integer이다.
64는 64bit integer라는 뜻.
4. Neural Network 만들기
# Build NN
class Net(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
Net_Out = self.layer(x)
return Net_Out
PyTorch에서 Neural Network을 정의하고 사용하려면
Net이라는 class를 nn.Module을
상속받아 만든 뒤에 사용해야 한다.
여기에 쓰이는 파이썬 핵심 문법은
아래 유튜버 분의 영상을 참고해서 공부했다.
Net class 안에는 flatten method가 있다.
하는 역할 자체는 2D data를 1D로 쭉 펴는거라
비슷한 function인 view랑 하는 역할은 같다.
단, view의 경우엔 output이 multi-dimensional로 나오도록
option을 줄 수 있기 때문에
무조건 1D로 펴는 flatten 보다는 좀 더 범용적이다.
그 뒤, layer로 정의되는 method는
nn.Squential을 가져와서 network architecture를 정한다.
여기서 nn.Linear는 fully-connected (FC) layer를 뜻하며,
전체 network가 FC layer 및 activation function (ReLU)으로만
이루어져 있으므로, 784-512-512-10의 size를 갖는
Multi-Layer Perceptron (MLP) architecture에 해당한다.
각 layer의 첫번째 argument는 input activation의 size,
두번째 argument는 output activation의 size이다.
예를 들어 첫번째 FC layer에서는 28×28 image가 들어와서
512개의 neuron이 output으로 나간다.
여기서 Softmax layer는 보이지가 않는데,
Loss Function을 Cross Entropy로 사용하기 때문에 그렇다
(nn.CrossEntropyLoss에 Softmax가 포함되어 있음).
아래 영상 참고.
신기한 점이 있는데, Net class를 쓸 때는
batch_size에 대한 parameter를 넣어서
관리할 필요가 없다는 점이다.
예를 들어, 첫번째 layer는 사실
28×28 image가 batch_size 만큼 들어오지만
뒤에 나오는 train function에서도 딱히 이걸 control하는
code를 필요로 하지도 않는다.
nn.Module내에서 이걸 알아서 잘 관리하는걸까?
자세히는 모르겠지만, 초보자도 잘 접근할 수 있도록
최대한 도와준다는 느낌이 들어서 좋다.
그 뒤에 나오는 forward method에서는
앞에서 정의한 network architecture를
feedforward path에 넣는 과정에 해당한다.
우선, input image가 2D이고
FC layer는 1D만 처리할 수 있으므로
flatten method로 이걸 펴준다.
그 후 앞에서 layer를 활용해 input data x를 넣고
output activation을 얻어 return 한다.
5. Training Function 만들기
# Build Train Function
def train(dataloader, model, loss_fn, optimizer):
pbar = tqdm(dataloader, desc=f'Training')
for batch, (X, y) in enumerate(pbar):
# X, y = X.to(device), y.to(device)
# Feedforward
pred = model(X)
# Calc. Loss
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
PyTorch Tutorial에서는 위와 같이 train function을
따로 만들어 관리하는 방법을 소개하고 있다.
여기서 dataloader argument에는 trainloader를 넣어주면 된다.
원래 Tutorial code를 보면 training set의 size를 구하기 위해
len(dataloader.dataset)을 구하는 과정이 있는데,
나는 보기 쉽고 직관적인 tqdm library를 사용하기로 했기에 지웠다.
train function 내에서는 mini-batch (batch_size) 단위로 training이 이루어지고,
이 짓을 전체 training set에 대해 모두 수행한다.
앞에서 설명했듯, DataLoader의 iterable한 특성 덕분에,
enumerate와 함께 for loop에 넣어주기만 해도
batch_size 만큼 data를 알아서 쏙쏙 빼내면서 loop을 돌려준다.
- FashionMNIST의 training set에는 60,000개의 image가 존재한다.
- batch_size를 64로 정했으므로, for loop을 만들어 돌린다면 for loop이 937.5번, 즉 938번 돌면 된다. 여기서 938을 number of batches라 부른다. 따라서, 위 for loop의 batch는 0부터 937까지 돌아간다.
- for loop의 마지막 iteration에서 937.5의 0.5, 즉 32개짜리 batch를 처리하는 code는 따로 짤 필요가 없다. 위에서 언급했듯 DataLoader가 알아서 처리해준다.
- 모든 batch에 대해서 training을 한 번 끝낸 단위를 epoch이라 부른다. 이 예제의 경우, for loop이 938번 돌면 1번의 epoch이 지난 것이다.
그 아래에는 X, y를 다시 정의하는 code가 있는데,
(X.to(device)에 해당)
CUDA를 사용해서 PyTorch를 돌리는 경우 연산속도를 빠르게 해주려고
GPU에다가 tensor를 옮겨다놓는 과정이다.
나는 노트북에서 돌리는 상황이고 내 GPU는
CUDA 지원 모델이 아니고 해서 ㅠㅠ 그냥 주석처리 해놨다.
나중에 Colab이나 데스크탑에서 돌려볼 때
주석 해제한 다음에 써 볼 계획이다.
그 아래에는 feedforward를 실행시키는 code가 있다.
여기서 model은 아까 우리가 정의한 Net class를
variable로 정해 넣어놓은 것을 말한다.
그냥 Net이면 Net, model이면 model 하나만 쓸 것이지
굳이 또 variable 이름까지 바꿔가면서
code를 짜야 하나 .. 싶은 생각이 들었는데,
아마 하나의 파이썬 코드 내에서 정의하는
Neural Network가 Net1, Net2 ... 이런식으로 좀 많다면
이름을 따로 둘 필요는 있을 것 같다.
아무튼 여기서 또 신기한 점이 있는데,
model에다가 input image X를 넣고
그걸 다시 다른 변수인 pred로 정의만 했는데
feedforward가 실행되어 버린다는 점이다.
엥? Net class에서 forward method를 정의했는데 이걸 따로 call 할 필요가 없나?
forward를 따로 call 하지도 않았는데 어떻게 결과가 제대로 나오는게 가능하지 ..?
라는 생각이 제일 처음 들었고
그래서 처음엔 이 code가 어떻게 돌아가는건지
전혀 감이 잡히지 않았다.
결론부터 말하자면, model에 input X를 넣자마자
forward가 실행되며, 이는 nn.Module에 이미 설정되어 있다.
이것 또한 code의 간결성,
그리고 초보자의 진입장벽을 낮추기 위한
PyTorch의 배려가 아닐까나 ㅋㅋㅋ
PyTorch Tutorial에 따르면, forward method는
따로 call 하지 말라고 안내한다.
(model.forward() 를 직접 호출하지 마세요! 라고)
따라서 그냥 저렇게 쓰면 된다.
신경망 모델 구성하기 — PyTorch Tutorials 1.9.0+cu102 documentation
Note Click here to download the full example code 파이토치(PyTorch) 기본 익히기 || 빠른 시작 || 텐서(Tensor) || Dataset과 Dataloader || 변형(Transform) || 신경망 모델 구성하기 || Autograd || 최적화(Optimization) || 모델 저
tutorials.pytorch.kr
그 뒤로는 loss를 구하는 code가 나오며,
여기에는 train의 argument로 넣은 loss_fn이 사용된다.
뒤에 나오겠지만, 이 예제에서는 Cross Entropy가 사용되었다.
optimzer.zero_grad는 for loop이 돌면서 training이 진행되는 동안
이전 iteration에서 계산된 gradient가 남아있으면 안 되므로
이걸 0으로 만들어준다는 뜻이다.
여기에는 train function의 4번째 argument로 들어오는
optimizer가 사용되며, torch.optim library에서 하나 골라서 쓰면 된다.
뒤에 나오겠지만, 이 예제에서는 Stochastic Gradient Descent가 사용되었다.
loss.backward는 Backpropagation을 돌리기 위해
Chain Rule을 이용, Neural Network에서 사용된
parameter들의 gradient를 계산하는 code이다.
optimizer.step은 계산된 gradient를 가지고
Neural Network의 weight/bias를 update하는 code이다.
6. Test Function 만들기
# Build Test Function
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
loss, correct = 0,0
with torch.no_grad():
for X, y in dataloader:
# X, y = X.to(device), y.to(device)
pred = model(X)
loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
loss /= num_batches
correct /= size
print(f'Test Accuracy: {(100*correct):>0.1f}% Loss: {loss:>8f} \n')
return 100*correct, loss
train function과 마찬가지로, dataloader에는 testloader가 들어가면 된다.
test set의 size를 구하는 code가 나오는데,
dataset의 length를 구하려고 하면 data의 개수가 튀어나오는 것을 이용해
len method를 이용한 것이다.
이것도 PyTorch 내 규칙인데, 내가 만약 custom dataset을 만들었다고 치면
__len__ method를 새로 정의해서 data 개수가 출력되도록 따로 설정해줘야 한다.
num_batches는 위에서 설명한 바와 같다.
DataLoader의 length를 구하려고 하면 batch_size를 고려하여
batch의 개수를 계산해준다.
size와 num_batches를 구하는 이유는 뒤에서
loss/accuracy를 계산해주기 위함이다.
model.eval을 호출하면 Dropout 이나 Batch Normalization과 같이
training 때와 inference 때 하는 역할이 다른 친구들을 적절하게 설정해준다.
예를 들면, Dropout은 training시 무작위로 neuron 및 그 neuron과 연결된 weight들을
0으로 만들어 버린 뒤 backpropagation을 하여 regularization 역할을 하도록 하고,
inference시에는 이러한 무작위 Dropout을 실행하지 않는다.
따라서 training을 할 때만 이게 동작하도록 하고
inference를 할 때는 동작을 하지 않도록 꺼놔야 하는데,
해당 역할을 model.eval이 한다.
이 예제에서는 Dropout이나 Batch Normalization이 사용되지 않았지만,
나중에 활용될 일이 있겠지 싶어서 그냥 놔뒀다.
torch.no_grad는 나 지금 inference 할 거니까
Neural Network의 parameter들에 default로 설정되어 있던
gradient tracking 하지마 라는 의미이다.
inference 할 때마다 parameter들의 gradient tracking을 계속 하면
연산 속도가 느려지므로 설정해두는 것이다.
for loop 내에서 feedforward하는 과정은
train function에서 하던 것과 동일하게 model에 input X만 넣어주면 된다.
그 뒤에는 loss를 구하는 과정이 나온다.
loss_fn의 결과로 나오는 data는 파이썬 constant도 아니고 NumPy array도 아닌
tensor이므로, item을 이용해 scalar 값을 빼낸다.
그리고 내가 만든 Neural Network를 이용해
예측한 결과가 맞았는지 틀렸는지 여부를 계산하고
이걸 토대로 accuracy를 구하는 code가 나온다.
먼저, pred.argmax(1) == y는 classification 결과를 체크하는 과정이다.
여기서 pred의 output은 batch_size × num_labels의 size를 갖는 tensor이며,
우리가 원하는 건 batch_size와 같은 size의 결과 data 이므로
argmax 안의 argument에 1이 들어간다. 여기서 argmax의 argument는 axis이다.
보통 NumPy나 Torch로 argmax를 돌리면 input array를 넣어주고
그 다음 argument로 axis를 넣어주는데 (np.argmax / torch.argmax),
위 code의 경우 tensor에다가 바로 argmax를 갖다 꽂는 방식이므로
torch.Tensor.argmax 문법이 된다. 따라서 argument는 axis이다.
torch.Tensor.argmax — PyTorch 1.9.1 documentation
Shortcuts
pytorch.org
이렇게 pred와 true label (y)을 비교하는 과정에서 나온 결과의 datatype은
일반적인 Python내 boolean이 아니라
torch([True]) 혹은 torch([False])와 같은 tensor format이 된다.
따라서 이걸 tensor format은 유지하면서
내부 datatype만 floating point로 바꾸는 것이 가능하며,
(일반 Python boolean으로 저런 방식으로 datatype 바꾸려고 하면 에러남)
정해진 batch_size 내에서 몇 개가 실제 true label과 일치하는지 확인하기 위해
sum을 적용한 뒤 item을 이용해 tensor 밖으로 끄집어낸다.
Loss는 epoch 단위로 average를 하여 표기하는 경우가 많다.
Training을 한 epoch 돌린 뒤 batch_size만큼의 test set을 Neural Network에 넣어서
loss를 체크해 보고, 다시 한 epoch 더 돌려보고 .. 하는 식으로.
따라서, loss는 test set내에 있는 모든 data에 대해 계산된 결과여야 유의미하며
batch_size만큼 뽑아서 계산한 loss를 num_batches 만큼 for loop에서 더해줬으니,
for loop 바깥쪽에서 num_batches로 나누어준다.
즉, 여기서 계산되는 loss는 averaged loss over num_batches이다.
반면, accuracy는 correct variable에서 test data의 개수로 나눠주면 된다.
Loss는 training을 위해 batch_size만큼 뭉텅이 단위로 계산되지만
accuracy는 그렇지 않기 때문.
PyTorch Tutorial에는 test function의 output이 나가지 않지만,
나는 accuracy와 loss를 받아내 plot을 해보고 싶어서
return code도 추가해주었다.
7. Neural Network의 Training / Evaluation
############################################################
# Run the Training and Evaluation
############################################################
# Generate the Model
model = Net().to(device)
# Set the Training Parameters
lr = 1e-3
loss_fn = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=lr)
# Plot
fig = plt.figure(figsize=(20,5))
line1, line2 = plt.plot([],[],[],[])
plt.clf()
# Train the Network
epochs = 100
for t in range(epochs):
print(f'----- Epoch {t+1} -----')
train(trainloader, model, loss_fn, optimizer)
accuracy, loss = test(testloader, model, loss_fn)
# Add Accuracy & Loss to the Lines
line1.set_xdata(np.append(line1.get_xdata(), t+1))
line1.set_ydata(np.append(line1.get_ydata(), loss))
line2.set_ydata(np.append(line2.get_ydata(), accuracy))
fig.add_subplot(1,2,1)
plt.plot(line1.get_xdata(), line1.get_ydata(), color='red')
plt.plot(line1.get_xdata(), line1.get_ydata(), 'o', color='red')
plt.xlabel('Epoch', fontsize=12); plt.ylabel('Loss', fontsize=12)
fig.add_subplot(1,2,2)
plt.plot(line1.get_xdata(), line2.get_ydata(), color='blue')
plt.plot(line1.get_xdata(), line2.get_ydata(), 'o', color='blue')
plt.xlabel('Epoch', fontsize=12); plt.ylabel('Accuracy', fontsize=12)
plt.tight_layout()
plt.autoscale()
plt.show()
앞서 정의한 train / test function들을 실제로 실행하는 파트이다.
앞서 말했듯, model은 Net class를 가지고 새롭게 정의한 variable에 해당한다.
여기서도 .to(device)가 쓰였는데, CUDA를 위한 것이니 빼도 상관없다.
lr은 learning rate이다.
계산된 gradient 값을 얼마나 크게크게 update 할 것인지를 정하는 변수인데,
회로하는 사람이 보기엔, 이 개념은 Digital PLL의
proportional path gain (β)과 매우 유사한 것 같다.
지금은 lr이 고정되어 있지만, training이 진행되면서
좀 더 미세조정을 하기 위해 lr 값을 더 작은 값으로 바꿔가는 식의
training 기법도 있으니 나중에 다뤄볼 수 있다면 다뤄봐야겠다.
(Type-I Digital PLL에서도 β를 줄여놓으면 limit cycle의 크기가 감소하므로 매우 유사하다.
어차피 Neural Network든 PLL이든 둘다 feedback mechanism이니까)
그 뒤로는 앞서 언급했듯 Cross Entropy 기반의 Loss Function,
Stochastic Gradient Descent (SGD) 기반의 Optimizer를 설정하는 code가 있다.
여기서 model.parameters()는 내가 만든 Neural Network에 있는
weight/bias와 같은 network parameter들이다.
그 아래로는 몇 epoch을 돌릴 것인지 정하는 code 및 plot을 하는 code들이 있다.
여기서는 대충 100번 epoch을 돌려보기로 했는데,
실제로는 test accuracy를 봐가면서 몇 epoch까지 돌릴 것인지
designer가 정해줘야 한다.
training epoch이 많아진다고 무조건 좋은 것은 아니기 때문인데,
내 Neural Network가 training set에 점점 overfitting이 되면
어느 시점 이후부터는 test accuracy가 조금씩 떨어진다.
이런 걸 좀 관찰하고 싶어서 미리 plot하는 code도 짜본 것.
아무튼, code를 돌리면 아래와 같은 progress 창을 볼 수 있다.
tqdm library 덕분에 percent bar 형태로 진행과정이 깔끔하게 잘 나온다.

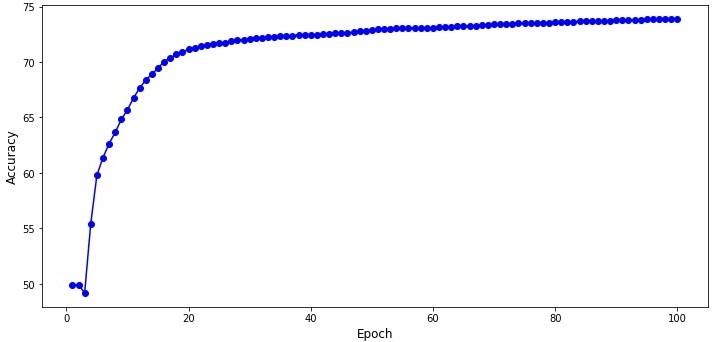

100번의 epoch을 돌린 결과, test accuracy 및 loss를 plot 하면 위와 같다.
Epoch 수를 더 늘려보면 accuracy가 올라갈 것 같기는 한데,
이 Network는 MLP이므로 큰 기대는 하지 않는게 좋다.
대신, CNN을 사용해보면 훨씬 큰 accuracy를 얻을 수 있을 것이다.